



The ultimate office space playlist: The data way
SQL: INTERSECT (and how UNION is different); Excel: Get data from JSON file
TL;DR:
Technically:
Excel: Get Data From file → JSON
SQL: INTERSECT; REPLACE(); LOWER()
Story Summary:
December 2022, we experienced another round of layoffs at the startup I used to work in. Empty space. Sad atmosphere. We wanted to create a mutually loved playlist to be listened to for all of the remaining team members to sing along to. This meant for both, YouTube Music and Spotify users.
So I took it on myself to run a MVP style project. I created the ultimate, the grooviest, of shared office space all-liked playlist! (well, with English bias…). Something quick and dirty to raise our spirits.
This is a re-creation of what I’ve done back then.
Quick introduction to INTERSECT (and how it’s different to UNION)
INTERSECT returns the common records that exist in both of the result sets produced by two or more SELECT queries. The resulting dataset only includes unique rows that appear in the tables, and the column structures must match.
Importantly, INTERSECT happens after the SELECT in terms of order of operations.
For example, if you have two tables listing songs liked by different employees, you can use INTERSECT to quickly find songs that are liked by both, helping you curate a mutual playlist for the office.
Let's clarify how INTERSECT is different to UNION:
UNION combines the result sets of two or more SELECT queries into a single result set, eliminating duplicate rows. Unlike INTERSECT, which only returns rows common to each table, UNION returns all unique rows from both tables.
For example, if you have two lists of songs names from different albums, using UNION would give you a single list containing all unique songs across both albums.Quick illustration for folks who need less abstract and more visualized example:


Google Takeout: Get your YouTube Music data
Do a quick googling and you’ll find Google Takeout where you are easily instructed how to request to have your data prepared for you to download. Make sure you choose to get it in CSV format and choose just what’s relevant for you.
We’ll be working with the “music-library-songs” csv.


Google prepares this data fast. You’ll soon enough have it ready. Just download it.

Get your Spotify Music data
You have to be a premium Spotify user for getting the desired “yourLibrary” data file (all your liked songs, albums, playlists, etc.).
As I am no longer one, in here I re-read how the structure of their JSON is and instructed ChatGPT to generate data accordingly (though I told it to go wild and create input as it pleases when it comes to songs etc.).
But making a request to get the data from Spotify is pretty straightforward:
You go online to their website www.spotify.com →
login to your user →
Privacy Settings →
There you have a sub section called “Download your data.”

The data is not ready as fast as Google sends it but you will not be waiting long before it gets to you.

Note: as you may notice, there will likely be a bias against non-English texts. Hebrew, for instance, often ends up as a weird gibberish style text.
Excel: Prepare the Spotify data from JSON to CSV
Although it’s possible to load into Microsoft SSMS the JSON files right away, I’ve found it more useful to generally know how to handle JSON files using Excel.
Data → Get Data → From File → From JSON

Click the green text to dig deeper into the data. In the below image, it’s “Record”.
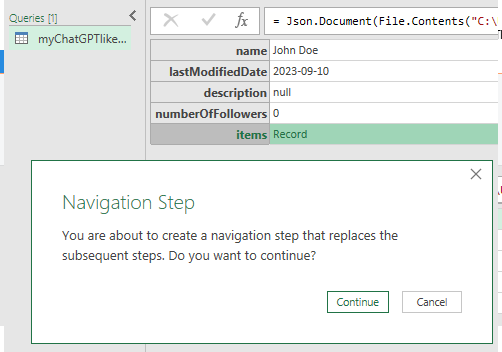
Choose each time which you’d like to expand as their structures are different. Later combine. Also, the Convert Into Table is a useful feature that needs clicking on to allow multi-expansions of arrays/objects.

Clicking the Convert to Table, you can expand each Record within likedSongs.

You may change the name of the first column to easily identify the source being expanded. Note the difference in signs which columns can be expanded and which cannot, as shown in the image.

Then click the Close & Load button.
After I finished with linkedSongs, I did the same for the likedAlbums and likedPlaylists due to their different structures. I chose to open only the relevant columns/variables.

I then combined them all into one table. If there were many rows, it would’ve been easier to import each to SQL using INSERT BULK and then using UNION.

That’s it for the Spotify data, taken from JSON file into Excel. I later converted it into CSV as I imported it to Microsoft’s SSMS (SQL Server Management Studio).
*For the record, I did not run due diligence on the correctness of the data that ChatGPT created.
Create & insert the data
You can download the data I used for this example:
“myChatGPTlikedSpotifyLibrary” JSON
(or, in case you want to skip the JSON & Excel part, click here for the spotify_liked_library CSV);
… or even better, get from Google & Spotify your own data with your friends & colleagues. Enjoy some tunes together :)
CREATE DATABASE mutual_office_music;
GO
USE mutual_office_music;
GO
-------------------------------------
--drop table spotify_music_emp1
CREATE TABLE spotify_music_emp1 (
artistName NVARCHAR(255),
trackName NVARCHAR(255),
albumName NVARCHAR(255)
);
GO
BULK INSERT spotify_music_emp1
FROM 'C:\Users\....\Desktop\spotify_liked_library.csv'
WITH (
FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR = '\n',
TABLOCK
);
GO
---
--drop table YouTube_music_emp2
--pay attention that you might need to remove the space between
--the words (variables/columns) if you've downloaded your own data
-- or alternatively, use [Song URL] etc. when you create the tables.
CREATE TABLE YouTube_music_emp2 (
SongURL NVARCHAR(MAX),
SongTitle NVARCHAR(MAX),
AlbumTitle NVARCHAR(MAX),
ArtistNames NVARCHAR(MAX)
);
GO
BULK INSERT YouTube_music_emp2
FROM 'C:\Users\....\Desktop\music-library-songs.csv' --name of YouTubeMusicFile
WITH (
FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR = '\n',
TABLOCK
);
GOCreating the shared playlist with SQL
The order of operations means we can first clean a bit the data to try and increase matches (i.e. the SELECT clause runs first and after it the INTERSECT).
As far as I can remember, I quickly glanced at the data and removed some capitalization variances as well as: ‘, commas, dots, question, exclamation and quotation marks in the data which could easily be cleaned out.
However, I did not handle the gibberish created by non-English/Latin letters and the diacritic marks (e.g. ä, ö, ü, å). The idea was to invest minimal time into this playlist & we had non-Hebrew folks at the office too, so a bias against Hebrew songs was actually welcomed.1
Originally, I’ve had about 5-7 different files provided by different employees, but the concept is the same.
SELECT [artist names] = REPLACE(
REPLACE(
REPLACE(
REPLACE(
REPLACE(
REPLACE(
LOWER(ArtistNames)
, '''','')
,',','')
,'.','')
,'?','')
,'!','')
,'"','')
, [song name] = REPLACE(
REPLACE(
REPLACE(
REPLACE(
REPLACE(
REPLACE(
LOWER(SongTitle)
, '''','')
,',','')
,'.','')
,'?','')
,'!','')
,'"','')
, [album name] = REPLACE(
REPLACE(
REPLACE(
REPLACE(
REPLACE(
REPLACE(
LOWER(AlbumTitle)
, '''','')
,',','')
,'.','')
,'?','')
,'!','')
,'"','')
FROM YouTube_music_emp2
INTERSECT
SELECT [artist names] = REPLACE(
REPLACE(
REPLACE(
REPLACE(
REPLACE(
REPLACE(
LOWER(artistName)
, '''','')
,',','')
,'.','')
,'?','')
,'!','')
,'"','')
, [song name] = REPLACE(
REPLACE(
REPLACE(
REPLACE(
REPLACE(
REPLACE(
LOWER(trackName)
, '''','')
,',','')
,'.','')
,'?','')
,'!','')
,'"','')
, [album name] = REPLACE(
REPLACE(
REPLACE(
REPLACE(
REPLACE(
REPLACE(
LOWER(albumName)
, '''','')
,',','')
,'.','')
,'?','')
,'!','')
,'"','')
FROM spotify_music_emp1The output based on the example set:

I hope you enjoyed from this quick introduction to INTERSECT.
Feel free to comment and to connect :)
If I’d wanted to enhance the analysis nowadays then I’d likely just add a user-defined function to handle all the non a-z A-Z 0-9 letters or so and add a condition to remove matches of nulls (of artist names, songs, albums, which weren’t originally matching).